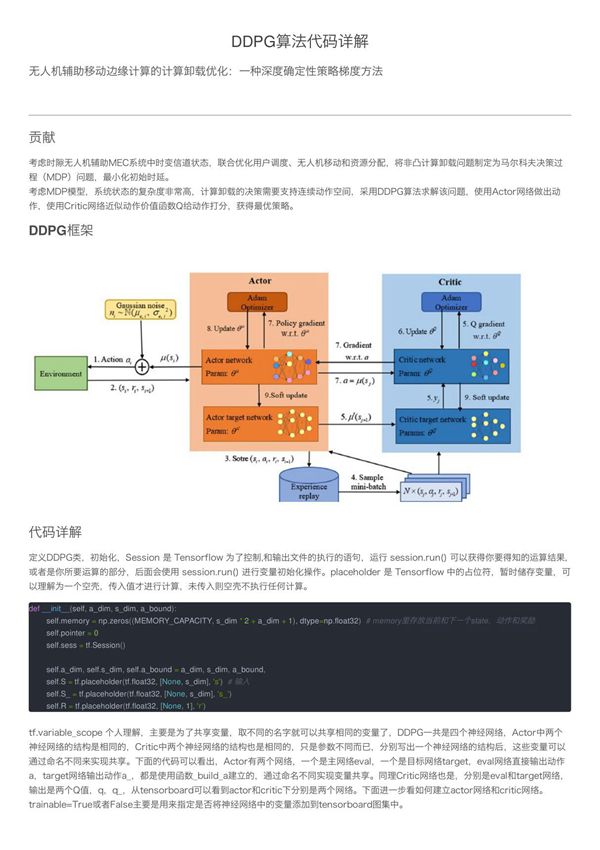
深度确定性策略梯度算法(DDPG)是一种结合了深度Q网络(DQN)和确定性策略梯度(DPG)的无模型强化学习算法,特别适用于连续动作空间的控制问题。DDPG通过Actor-Critic框架实现,其中Actor网络负责输出确定性动作,而Critic网络评估动作的价值。该算法采用经验回放机制和目标网络技术来提高训练的稳定性。以下代码实现展示了DDPG的核心组件,包括网络结构定义、经验回放缓冲区、动作探索策略以及训练过程。代码注释详细解释了每个关键步骤的功能和实现原理,帮助理解DDPG算法的工作机制和实际应用方式。